想必有很多人不太理解SonarQube中关于代码覆盖率的计算方法。对于覆盖率、分支覆盖率、分支覆盖率等这些的区别
首先,先来看下覆盖率的图,再根据图上SonarQube汉化的术语来说明下:
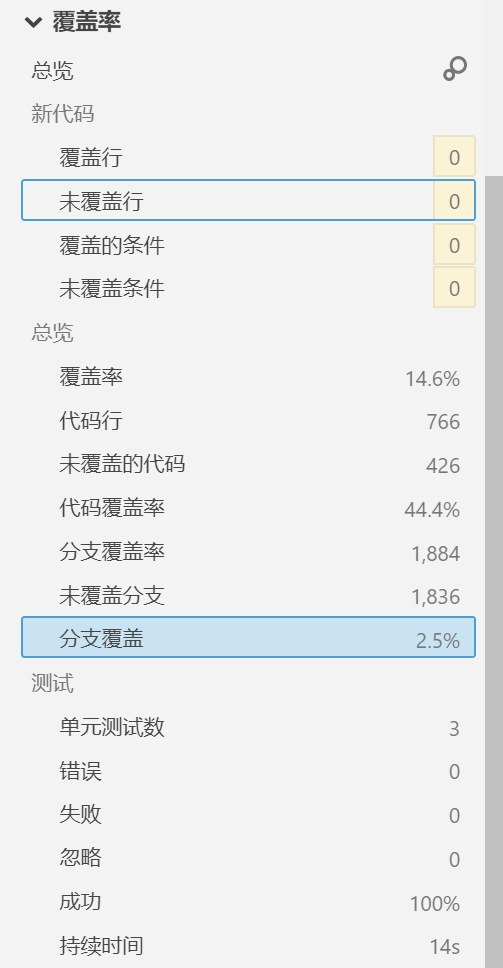
这里由于翻译的问题,所以会导致有点不明所以。搞不懂为啥要按照下面的公式计算。所以这里对公式中的术语做个简单的说明
- CT:条件至少一次为“true”的分支
- CE:条件至少一次为“false”的分支
- B:分支的总数量
- EL:可执行的代码行数
- LC:覆盖的行数
覆盖率
覆盖率的计算是一个简单的公式:
覆盖率 = (CT+CF+LC)/(2B+EL)
按照图中汉化的术语来计算则:
CT+CF= 分支覆盖率-未覆盖分支
2B= 分支覆盖率
EL= 代码行
LC= 代码行-未覆盖的代码
SonarQube中的这个覆盖率,就是综合考虑行覆盖率和分支覆盖率后计算出来。为什么既要考虑行覆盖率又要考虑分支覆盖率呢,下面会给出解释。
行覆盖率
行覆盖率是一个简单的公式
行覆盖率= LC/EL
这种覆盖率统计方式是最为基础的,它可以用于体现参测代码中已被执行和未被执行的代码行(语句),从而可以进一步推断代码的逻辑覆盖是否全面。
分支覆盖率
分支覆盖率的公式如下:
分支覆盖率= (CT+CF)/2B
这种覆盖率统计方式是用于统计代码中所有判断分支是否都被覆盖,如:
if (condition)
{
Operation_1();
}
else
{
Operation_2();
}
语句就会根据 condition 的值产生两个不同的分支操作,那么在统计分支覆盖时,就需要对两个分支都进行校验。值得注意的是,上例中的代码,其分支覆盖可以被行覆盖所取代,也就是说若上面代码的行覆盖率为100%, 则其分支覆盖率亦为100%。
但是如果python常见的那种三元表达式的条件判断,如:
condition ? Operation_1() : Operation_2();
在行覆盖率中,只要这一行执行过,就为100%,所以只看行覆盖率,就不太行,需要综合考虑二者