CI和CD是现在开发、测试、运维必不可少的工作流程
主流 CI/CD 应用
对比经过一些比较和调研,由于团队主要使用java语言开发,最终选择了 Jenkins作为主力 CI 工具。
下面这张表总结了主流的几个 CI/CD 应用的特点
项目名称 | 开发语言 | 配置语言 | 公有云服务 | 私有部署 | 备注
--------|-------|--------|----------|--------|------|--------
Travis CI | Ruby | YAML | 有 | 不支持 | 公共项目免费,私有项目 $69/单进程, $129/2 进程
Circle CI | Clojure | YAML | 有 | 不支持 | 单进程免费,$50/加 1 进程
Gitlab CI | Ruby | YAML | 有| 支持 | 绑定 Gitlab 代码管理
Jenkins | Java | Groovy/YAML | 无| 支持 | 最新版本支持pipeline文件
Drone | Go | YAML | 有 | 支持 | Cloud 版本不支持私有项目,自建版本无此限制
Travis CI 和 CircleCI 是目前占有率最高的两个公有云 CI,易用性上相差无几,只是收费方式有差异。由于不支持私有部署,如果并行的任务量一大,按进程收费其实并不划算;而且由于服务器位置的原因,如果推送镜像到国内,速度很不理想。
Gitlab CI 虽然好用,和 Gitlab 是深度绑定的,但是由于我们需要多个环境的部署持续集成部署,gitlab-ci并不能很好的做到这一点。
Jenkins 作为老牌劲旅,也是目前市场占有率最高的 CI,几乎可以覆盖所有 CI 的使用场景,由于使用 Java 编写,配置文件使用 Groovy 语法,非常适合 Java 为主语言的团队。Jenkins 显然是可以满足我们需要的,目前也有 了使用 YAML 书写 CI 配置,所以最终选择了 Jenkins 。
Drone是新兴技术,使用了go语言开发,结合各种插件,使用起来也很方便,但是考虑到本文发布的时候Drone才刚刚发布1.0的正式版,所以Drone仅为考虑的对象。待以后成熟了,再使用。
容器环境下一次规范的发布应该包含哪些内容
技术选型完成后,我想首先演示一下最终的成果,希望能直观的体现出 CI 对自动化效率起到的提升,不过这就涉及到一个问题:在容器环境下,一次发布应该包含哪些内容,其中有哪些部分是可以被 CI 自动化完成的。这个问题虽然每家公司各不相同,不过按经验来说,容器环境下一次版本发布通常包含这样一个 Checklist:
* [ ] 代码的下载构建及编译
* [ ] 运行单元测试,生成单元测试报告及覆盖率报告等
* [ ] 在测试环境对当前版本进行测试
* [ ] 为待发布的代码打上版本号
* [ ] 编写 ChangeLog 说明当前版本所涉及的修改
* [ ] 构建 Docker 镜像
* [ ] 将 Docker 镜像推送到镜像仓库
* [ ] 在预发布环境测试当前版本
* [ ] 正式发布到生产环境
看上去很繁琐对吗,如果每次发布都需要人工去处理上述的所有内容,不仅容易出错,而且也无法应对 DevOps 时代一天至少数次的发布频率,那么下面就来使用 CI 来解决所有问题吧。
CI 流程演示
为了对 CI 流程有最直观的认识,可以创建一个spring boot demo演示完整的流程,项目自动构建的 Docker 镜像会推送到 docker registry ,。为了方便说明,假设这个项目的核心文件只有一个jar包服务。
单人开发模式
目前这个项目背后的 CI 都已经配置部署好,假设我是这个项目的唯一开发人员,如何开发一个新功能并发布新版本呢?
1. Clone 项目到本地, 修改项目代码, 如将 Hello World 改为 Hello World V2。
2. git add .,然后书写符合约定的 Commit 并提交代码, git commit -m "feature: hello world v2”
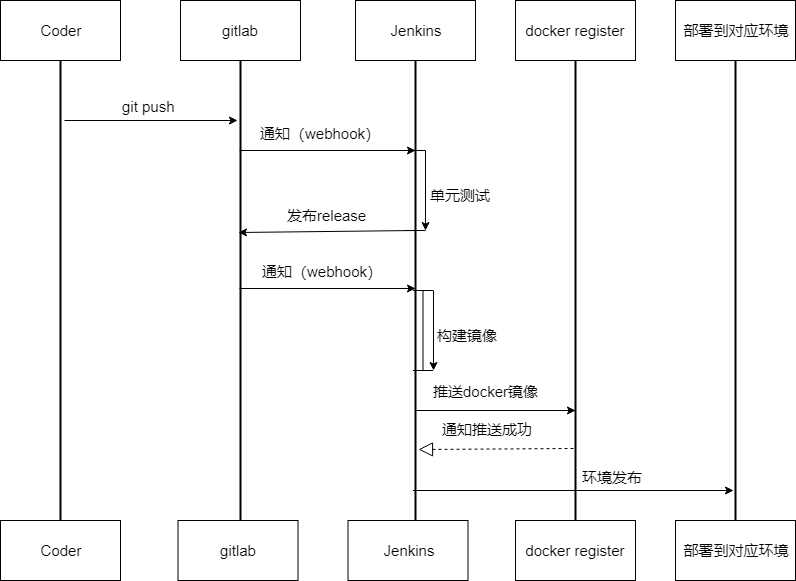
3. 推送代码到代码库git push,等待数分钟后,开发人员会看到单元测试结果,gitlab仓库会产生一次新版本的 release,release 内容为当前版本的 ChangeLog, 同时线上已经完成了新功能的发布。
虽然在开发者看来,一次发布简单到只需 3 个指令,但背后经过了如下的若干次交互,这是一次发布实际产生交互的时序图,具体每个环节如何工作将在后文中详细说明。
多人开发模式
一个项目一般不止一个开发人员,比如我是新加入这个项目的成员,在这个 Demo 中应该如何上线新功能呢?同样非常简单:
1. Clone 项目到本地,创建一个分支来完成新功能的开发, git checkout -b feature/hello-world-v3。在这个分支修改一些代码,比如将Hello World V2修改为Hello World V3
2. git add .书写符合规范的 Commit 并提交代码, git commit -m "feature: hello world v3”
3. 将代码推送到代码库的对应分支, git push origin feature/hello-world
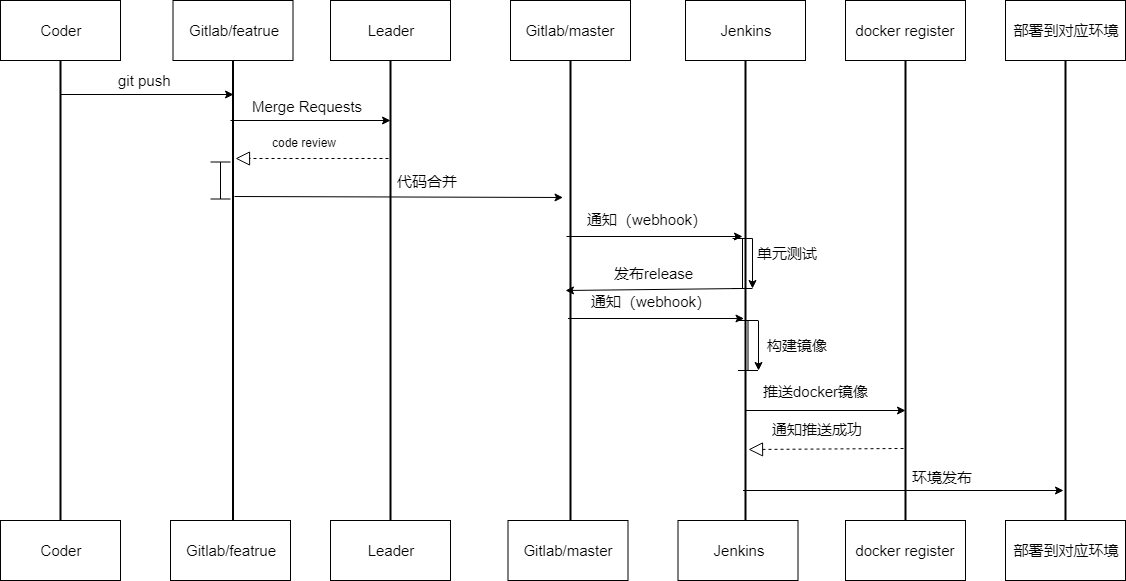
4. 如果功能已经开发完毕,可以向 Master 分支发起一个 Pull Request,并让项目的负责人 Code Review
5. Review 通过后,项目负责人将分支合并入主干,gitlab 仓库会产生一次新版本的 release,同时线上已经完成了新功能的发布。
这个流程相比单人开发来多了 2 个环节,很适用于小团队合作,不仅强制加入了 Code Review 把控代码质量,同时也避免新人的不规范行为对发布带来影响。实际项目中,可以在 gitlab 的设置界面对 master 分支设置写入保护,这样就从根本上杜绝了误操作的可能。当然如果团队中都是熟手,就无需如此谨慎,每个人都可以负责 PR 的合并,从而进一步提升效率。
GitFlow 开发模式
在更大的项目中,参与的角色更多,一般会有开发、测试、运维几种角色的划分;还会划分出开发环境、测试环境、预发布环境、生产环境等用于代码的验证和测试;同时还会有多个功能会在同一时间并行开发。可想而知 CI 的流程也会进一步复杂。
能比较好应对这种复杂性的,首选 GitFlow 工作流, 即通过并行两个长期分支的方式规范代码的提交。而如果使用了 gitlab,由于有非常好用的 Pull Request 功能,可以将 GitFlow 进行一定程度的简化,最终有这样的工作流:
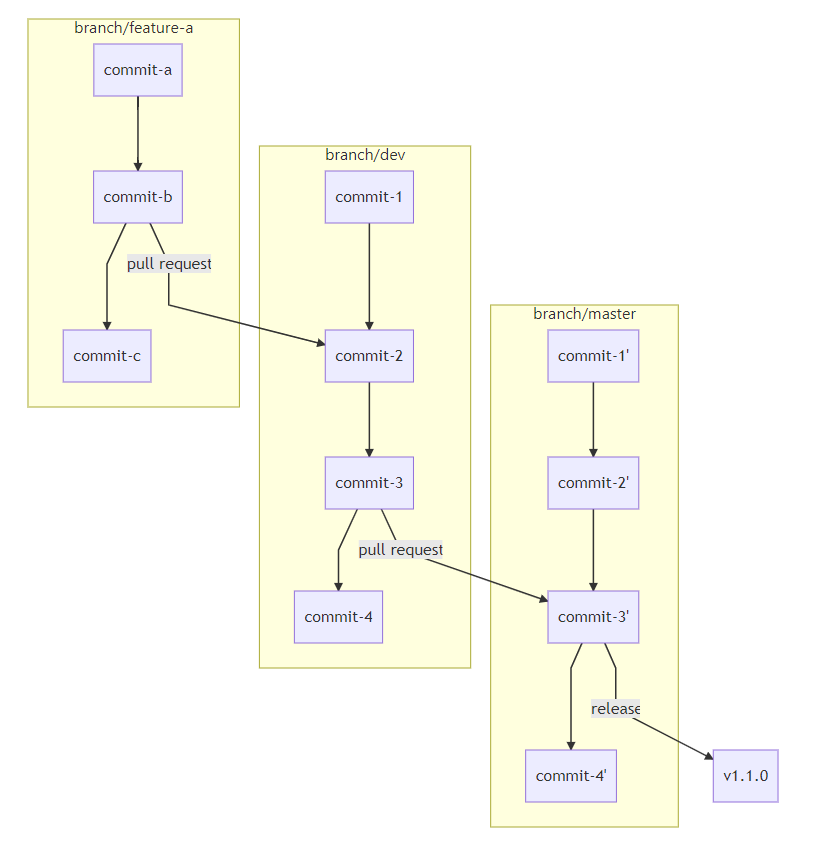
* 以 dev 为主开发分支,master 为发布分支
* 开发人员始终从 dev 创建自己的分支,如 feature-a
* feature-a 开发完毕后创建 PR 到 dev 分支,并进行 code review
* review 后 feature-a 的新功能被合并入 dev,如有多个并行功能亦然
* 待当前开发周期内所有功能都合并入 dev 后,从 dev 创建 PR 到 master
* dev 合并入 master,并创建一个新的 release
上述是从 Git 分支角度看代码仓库发生的变化,实际在开发人员视角里,工作流程是怎样的呢。假设我是项目的一名开发人员,今天开始一期新功能的开发:
1. Clone 项目到本地,git checkout dev。从 dev 创建一个分支来完成新功能的开发,git checkout -b feature/feature-a。在这个分支修改一些代码,比如将Hello World V3修改为Hello World Feature A
2. git add .书写符合规范的 Commit 并提交代码,git commit -m "feature: hello world feature A"
3. 将代码推送到代码库的对应分支,git push origin feature/feature-a:feature/feature-a
4. 由于分支是以feature/命名的,因此 CI 会运行单元测试,并自动构建一个当前分支的镜像,发布到测试环境,并自动配置一个当前分支的域名如 test-featue-a.fs.com
5. 联系产品及测试同学在测试环境验证并完善新功能
6. 功能通过验收后发起 PR 到 dev 分支,由 Leader 进行 code review
7. Code Review 通过后,Leader 合并当前 PR,此时 CI 会运行单元测试,构建镜像,并发布到测试环境
8. 此时 dev 分支有可能已经积累了若干个功能,可以访问测试环境对应 dev 分支的域名,如 test.fs.com,进行集成测试。
9. 集成测试完成后,由运维同学从 Dev 发起一个 PR 到 Master 分支,此时会 CI 会运行单元测试,构建镜像,并发布到预发布环境
10. 测试人员在预发布环境下再次验证功能,团队做上线前的其他准备工作
11. 运维同学合并 PR,CI 将为本次发布的代码及镜像自动打上版本号并书写 ChangeLog,同时发布到生产环境。
由此就完成了上文中 Checklist 所需的所有工作。虽然描述起来看似冗长,但不难发现实际作为开发人员,并没有任何复杂的操作,流程化的部分全部由 CI 完成,开发人员只需要关注自己的核心任务:按照工作流规范,写好代码,写好 Commit,提交代码即可。
接下来将介绍这个以 CI 为核心的工作流,是如何一步步搭建的。
Step by Step 构建 CI 工作流
Step.0: 基于 docker 部署 Jenkins
运行下面的命令直接启动Jenkins
docker run \
-u root \
--name jenkins \
-d \
--restart always \
-p 8080:8080 \
-p 50000:50000 \
-v jenkins-data:/var/jenkins_home \
-v /var/run/docker.sock:/var/run/docker.sock \
jenkinsci/blueocean
具体安装说明可以见我之前的文章Jenkins安装和简单使用,里面有详细的介绍说明
Step.1: 单人工作流,自动化单元测试与 Docker 镜像构建
为了方便说明,这里假设项目语言为 Java。
我们希望将代码打包成 Docker 镜像,根目录下增加了 Dockerfile 文件,这里直接使用 Java的官方镜像,构建过程只有 1 行COPY /target/*.jar /app.jar, 这样镜像运行后可以通过 http 请求看到index.html的内容。
至此我们可以将工作流改进为:
* 当 master 分支接收到 push 后,运行单元测试和构建操作
* gitlab发布一次webhook通知, 构建 Docker 镜像,并推送到Harbor镜像仓库
对应的 Jenkins 配置文件如下
pipeline {
environment {
CI = 'true'
CON_NAME = "xxxxx"
HAR_NAME = "test"
HAR_PASS = "Test12345"
SONARURL = "http://sonar.com.cn"
SONARURL_token = "fa0b0f7a5f12fbf7b120e1726b3e4db6ea040e8c"
}
agent any
tools {
maven "maven3.5.4"
}
stages {
stage('构建') {
steps {
echo '开始构建'
sh 'mvn -DskipTests clean package'
echo '构建成功'
}
}
stage('单元测试') {
steps {
echo '开始单元测试'
sh 'mvn test'
echo '单元测试成功'
}
}
stage('代码扫描') {
steps {
echo '开始代码扫描'
sh 'mvn sonar:sonar -Dsonar.host.url=${SONARURL} -Dsonar.login=${SONARURL_token}'
echo '代码扫描结束'
}
}
stage('镜像构建') {
steps {
echo '构建镜像并上传到harbor'
script {
//登陆使用的凭据需要提前在Jenkins中添加好
def customImage = docker.build("harbor.asoco.com.cn/${HAR_NAME}/${CON_NAME}:${env.GIT_BRANCH}-${env.BUILD_NUMBER}")
withDockerRegistry(credentialsId: 'har-test', url: 'http://harbor.asoco.com.cn') {
customImage.push("${env.GIT_BRANCH}-${env.BUILD_NUMBER}")
customImage.push("latest")
}
}
echo '删除本地镜像'
sh "docker image rm harbor.asoco.com.cn/${HAR_NAME}/${CON_NAME}:${env.GIT_BRANCH}-${env.BUILD_NUMBER}"
}
}
}
post {
failure {
echo '测试失败'
}
success {
echo '测试成功'
}
}
}
Step.2: GitFlow 多分支团队工作流
上面的工作流已经基本可以应付单人的开发了,而在团队开发时,这个工作流还需要一些扩展,只需要在上文基础上根据分支做一点调整即可。
对应的 Jenkins 配置文件如下
pipeline {
environment {
CI = 'true'
CON_NAME = "xxxxx"
HAR_NAME = "test"
HAR_PASS = "Test12345"
SONARURL = "http://sonar.com.cn"
SONARURL_token = "fa0b0f7a5f12fbf7b120e1726b3e4"
CON_PROT = "8080"
TEST_ENV = "xxxxx"
webhook = "https://oapi.dingtalk.com/robot/send?access_token=bfc4d57a02b5a6ea8axxxxxxxxx"
callphone = "186xxxxxxxx"
}
agent any
tools {
maven "maven3.5.4"
}
stages {
stage('构建') {
steps {
echo '开始构建'
sh 'mvn -DskipTests clean package'
echo '构建成功'
}
}
stage('单元测试') {
steps {
echo '开始单元测试'
sh 'mvn test'
echo '单元测试成功'
}
}
stage('代码扫描') {
steps {
echo '开始代码扫描'
sh 'mvn sonar:sonar -Dsonar.host.url=${SONARURL} -Dsonar.login=${SONARURL_token}'
echo '代码扫描结束'
}
}
stage('镜像构建') {
steps {
echo '构建镜像并上传到harbor'
script {
//登陆使用的凭据需要提前在Jenkins中添加好
def customImage = docker.build("harbor.com.cn/${HAR_NAME}/${CON_NAME}:${env.GIT_BRANCH}-${env.BUILD_NUMBER}")
withDockerRegistry(credentialsId: 'har-test', url: 'http://harbor.com.cn') {
customImage.push("${env.GIT_BRANCH}-${env.BUILD_NUMBER}")
customImage.push("latest")
}
}
echo '删除本地镜像'
sh "docker image rm harbor.com.cn/${HAR_NAME}/${CON_NAME}:${env.GIT_BRANCH}-${env.BUILD_NUMBER}"
}
}
stage('测试环境部署') {
agent { label "${TEST_ENV}" }
when {
beforeAgent true
branch 'test'
}
steps {
echo '开始环境部署'
sh "docker login -u ${HAR_NAME} -p ${HAR_PASS} harbor.com.cn"
sh "docker pull harbor.com.cn/${HAR_NAME}/${CON_NAME}:latest"
sh '''if [ $(docker ps -aq --filter name=^/${CON_NAME}$) ]; then docker stop ${CON_NAME} && docker rm ${CON_NAME};fi'''
//自动部署最新版本
sh '''docker run -d --name ${CON_NAME} -p ${CON_PROT}:${CON_PROT} harbor.com.cn/${HAR_NAME}/${CON_NAME}:latest --spring.profiles.active=test '''
echo '部署结束'
}
}
stage('接口测试') {
steps {
echo '开始接口自动测试'
sh '''
curl 'yapi.com'
'''
echo '测试结束'
}
}
}
post {
failure {
sh "./ding.sh ${webhook} ${callphone} ${CON_NAME} ${BUILD_ID} ${BRANCH_NAME} 测试 失败"
}
success {
sh "./ding.sh ${webhook} ${callphone} ${CON_NAME} ${BUILD_ID} ${BRANCH_NAME} 测试 成功"
}
}
}
* 团队成员从 dev 分支 checkout 自己的分支 feature/readme
* 向feature/readme提交代码并 push, CI 运行单元测试,构建镜像ci-demo:readme
* 功能开发完成后,团队成员向 test分支 发起 pull request , CI 运行单元测试
* 团队其他成员 merge pull request, CI 运行单元测试,构建镜像ci-demo:test并部署到测试环境,测试人员开始测试
* 测试完成后,运维人员从 test向 master 发起 pull request,CI 运行单元测试,并构建镜像ci-demo:latest
* 运维人员 merge pull request, 并 release 新版本 pre-0.0.2, CI 构建镜像ci-demo:pre-0.0.2
Step.3: 语义化发布
上面基本完成了一个支持团队协作的半自动 CI 工作流,如果不是特别苛刻的话,完全可以用上面的工作流开始干活了。
不过基于这个工作流工作一段时间,会发现仍然存在痛点,那就是每次发布都要想一个版本号,写 ChangeLog,并且人工去 release。
标记版本号涉及到上线后的回滚,追溯等一系列问题,应该是一项严肃的工作,其实如何标记早已有比较好的方案,即语义化版本。在这个方案中,版本号一共有 3 位,形如 1.0.0,分别代表:
1. 主版本号:当你做了不兼容的 API 修改,
2. 次版本号:当你做了向下兼容的功能性新增,
3. 修订号:当你做了向下兼容的问题修正。
虽然有了这个指导意见,但并没有很方便的解决实际问题,每次发布要搞清楚代码的修改到底是不是向下兼容的,有哪些新的功能等,仍然要花费很多时间。
而语义化发布 (Semantic Release) 就能很好的解决这些问题。
语义化发布的原理很简单,就是让每一次 Commit 所附带的 Message 格式遵守一定规范,保证每次提交格式一致且都是可以被解析的,那么进行 Release 时,只要统计一下距离上次 Release 所有的提交,就分析出本次提交做了何种程度的改动,并可以自动生成版本号、自动生成 ChangeLog 等。
语义化发布中,Commit 所遵守的规范称为约定式提交 (Conventional Commits)。比如 node.js、 Angular、Electron 等知名项目都在使用这套规范。
语义化发布首先将 Commit 进行分类,常用的分类 (Type) 有:
* feat: 新功能
* fix: BUG 修复
* docs: 文档变更
* style: 文字格式修改
* refactor: 代码重构
* perf: 性能改进
* test: 测试代码
* chore: 工具自动生成
每个 Commit 可以对应一个作用域(Scope),在一个项目中作用域一般可以指不同的模块。
当 Commit 内容较多时,可以追加正文和脚注,如果正文起始为BREAKING CHANGE,代表这是一个破坏性变更。
以下都是符合规范的 Commit:
feat: 增加重置密码功能
fix(邮件模块): 修复邮件发送延迟BUG
feat(API): API重构
BREAKING CHANGE: API v3上线,API v1停止支持
有了这些规范的 Commit,版本号如何变化就很容易确定了,目前语义化发布默认的规则如下
| Commit | 版本号变更 |
|---|---|
| BREAKING CHANGE | 主版本号 |
| feat | 次版本号 |
| fix / perf | 修订号 |
有了这套规范,我们就可以清楚的知道,版本号是如何递增的,以及可以及时的追溯相关版本的问题。
具体如何将语义化发布加入 CI 流程中呢, semantic-release/exec 是 js 实现的,如果是 js 的项目,可以直接在package.json中增加配置项,而对于任意语言的项目,推荐在根目录下增加 配置文件release.config.js。这个配置目的是为了禁用默认开启的 npm 发布机制,可以直接套用。
{
"plugins": [
"@semantic-release/commit-analyzer",
"@semantic-release/release-notes-generator",
["@semantic-release/exec", {
"verifyConditionsCmd": "./verify.sh",
"publishCmd": "./publish.sh ${nextRelease.version} ${options.branch} ${commits.length} ${Date.now()}"
}],
]
}
有了这个例子:
verifyConditionsCmd命令./verify.sh将在验证条件步骤中执行
publishCmd命令./publish.sh 1.0.0 master 3 870668040000(为的版本发布1.0.0从分支master与3在提交时August 4th, 1997 at 2:14 AM)将在执行发布步骤
| Options | Description |
|---|---|
verifyConditionsCmd |
要在验证条件步骤期间执行的shell命令。请参阅 verifyConditionsCmd. |
analyzeCommitsCmd |
要在分析提交步骤期间执行的shell命令。请参阅 analyzeCommitsCmd. |
verifyReleaseCmd |
要在验证释放步骤期间执行的shell命令。请参阅 verifyReleaseCmd. |
generateNotesCmd |
要在生成注释步骤期间执行的shell命令。请参阅 generateNotesCmd. |
prepareCmd |
要在准备步骤中执行的shell命令。请参阅 prepareCmd. |
publishCmd |
要在发布步骤中执行的shell命令。请参阅 publishCmd. |
successCmd |
要在成功步骤中执行的shell命令。见 successCmd. |
failCmd |
要在失败步骤期间执行的shell命令。请参阅 failCmd. |
shell |
用于运行命令的shell。请参阅 execa#shell. |
execCwd |
执行shell命令时用作当前工作目录的路径。此路径与运行语义释放的路径相关。例如,如果语义释放运行/my-project并execCwd设置为,buildScripts则将执行shell命令/my-project/buildScripts |
来再次模拟一下流程,feature 分支部分与上文相同
* 从 test 向 master 发起 pull request,CI 运行单元测试,并构建镜像ci-demo:latest
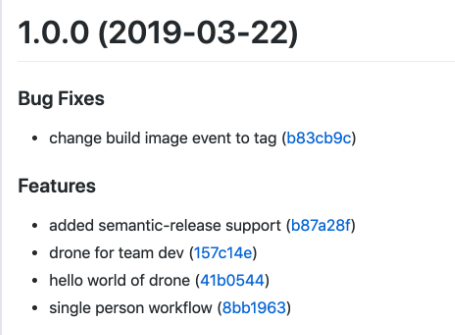
* merge pull request,CI 会执行单元测试并运行 semantic-release , 运行成功的话能看到 gitlab 新增 tag v1.0.0
* gitlab tag 再次触发CI 构建生产环境用 Docker 镜像ci-demo:1.0.0
最终我们能得到这样一个赏心悦目的 tag
后话
总结一下,本文展示了从 Hello World 到 单人单分支手动发布 到 团队多分支 GitFlow 工作流 到 团队多分支 semantic-release 语义化发布 ,如何从零开始一步一步搭建 CI 将团队开发、测试、发布的流程全部自动化的过程,最终能让开发人员只需要认真提交代码就可以完成日常的所有 DevOps 工作。
最终 Step 的完成品可以适配之前的所有 Step,如果不太在意实现细节的话,可以在此基础上稍作修改,直接使用。
然而写好每一个 Commit 这个看似简单的要求,其实对于大多数团队来说并不容易做到,在实施过程中,经常会遇到团队成员不理解为什么要重视 Commit 规范,每个 Commit 都要深思熟虑是否过于吹毛求疵等等疑问。
以 Commit 作为 CI 的核心,个人认为主要会带来以下几方面的影响:
1. 一个好的 Commit,代表着开发人员对当前改动之于整个系统的影响,有非常清楚的认识,代码的修改到底算 feat 还是 fix ,什么时候用 BREAKING CHANGE 等都是要仔细斟酌的,每个 Commit 都会在 ChangeLog 里“留底”,从而约束团队不随意提交未经思考的代码,提高代码质量
2. 一个好的 Commit 也代表开发人员有能力对所实现功能进行精细的划分,一个分支做的事情不宜过多,一个提交也应该专注于只解决一个问题,每次提交(至少是每次 push )都应该保持系统可构建、可运行、可测试,如果能坚持做到这些,对于合并代码时的冲突解决,以及集成测试都有很大帮助。
3. 由于每次发布能清楚的看到所有关联的 Commit 以及 Commit 的重要程度,那么线上事故的回滚也会非常轻松,回滚到哪个版本,回滚后哪些功能会受到影响,只要看 CI 自动生成的 Release 记录就一目了然。如果没有这些,回滚误伤到预期外的功能从而引发连锁反应的惨痛教训,可能很多运维都有过类似经历吧。
因此 CI 自动化其实是锦上添花而非雪中送炭,如果团队原本就无视规范,Commit 全是空白或者没有任何意义的单词,分支管理混乱,发布困难,奢望引入一套自动化 CI 来能解决所有这些问题,无疑是不现实的。而只有原本就重视代码质量,有一定规范意识,再通过自动化 CI 来监督约束,团队在 CI 的帮助下代码质量提高,从而有机会进一步改进 CI 的效率,才能形成良性循环。
**** 愿天下不再有难发布的版本。